Von 3 Tagen auf 5 Minuten: Wie Docker Compose meinem Kunden €150.000 im Jahr spart
Management Summary
In der modernen Software-Entwicklung kostet das Aufsetzen von Entwicklungs-, Test- und Abnahme-Umgebungen durchschnittlich 2-3 Tage pro Team und Release-Zyklus. Bei einem 7-köpfigen Entwicklerteam summiert sich das auf über €150.000 jährlich - reine Wartezeit, keine Wertschöpfung.
Mit einem durchdachten Docker Compose Setup lässt sich dieser Prozess auf unter 5 Minuten reduzieren. Dieser Artikel zeigt anhand eines realen SaaS-Projekts, wie das funktioniert - technisch fundiert, aber pragmatisch umsetzbar.
Key Takeaways:
- ROI: 99% Zeitersparnis beim Umgebungs-Setup
- Infrastructure as Code: Konsistenz von Dev bis Produktion
- Praxiserprobtes Setup für komplexe Multi-Service-Architekturen
- Security-Hardening ohne Komplexitäts-Overhead
Der Montag, an dem nichts funktionierte
Es ist 9:00 Uhr, Montag morgen. Das Entwicklerteam sitzt bereit, Sprint Planning ist durch, die User Stories sind priorisiert. Dann die Durchsage: "Wir müssen erst die neue Testumgebung aufsetzen, bevor wir loslegen können."
Was folgt, kennt jeder, der in der Software-Entwicklung arbeitet:
Der erste Entwickler installiert Postgres - Version 16, weil das gerade aktuell ist. Der zweite richtet Redis ein - mit anderen Konfigurationsparametern als in Produktion. Der dritte kämpft mit MinIO, weil die Bucket-Namen nicht stimmen. Und der DevOps-Engineer versucht verzweifelt, Traefik zum Laufen zu bringen, während alle anderen warten.
Am Dienstagmittag läuft endlich alles. Fast. Die Versionsstände stimmen nicht überein, die Konfiguration weicht von Produktion ab, und beim nächsten Update geht das Spiel von vorne los.
Die Rechnung ist brutal:
- 7 Entwickler × 16 Stunden × €80/Stunde = €8.960 für EINE Umgebung
- × 3 Umgebungen (Dev, Test, Abnahme) = €26.880
- × 6 Release-Zyklen im Jahr = €161.280
Und das sind nur die direkten Kosten. Nicht eingerechnet: Frustration, Kontext-Switches, verzögerte Releases.
Die Lösung: Infrastructure as Code - aber richtig
"Warum nutzt ihr nicht einfach Docker?" - Eine berechtigte Frage, aber sie greift zu kurz. Docker allein löst das Problem nicht. Kubernetes? Overkill für die meisten Projekte und oft komplexer als das ursprüngliche Problem.
Die Antwort liegt in der Mitte: Docker Compose als "Infrastructure as Code Light".
Mit einem gut strukturierten Docker Compose Setup wird aus drei Tagen Setup-Hölle ein einziger Befehl:
git clone projekt-repo
docker compose --profile dev up -d5 Minuten später: Alle Services laufen, konsistent konfiguriert, mit den richtigen Versionen.
Klingt zu gut um wahr zu sein? Schauen wir uns an, wie das in der Praxis aussieht.
Der Stack: Ein reales SaaS-Beispiel
Unser Beispiel stammt aus einem echten Projekt - einer modernen SaaS-Anwendung mit typischer Microservice-Architektur:
Frontend-Tier:
- Traefik als Reverse Proxy und SSL-Termination mit Let's Encrypt
- React UI mit Vite, TypeScript, ShadCN und TailwindCSS
Backend-Tier:
- Spring Boot Microservice als API-Layer
- PostgreSQL für relationale Daten
- Weaviate Vector-DB für Embeddings und semantische Suche
- Redis für Caching und Session-Management
- MinIO als S3-kompatibler Object Storage
- OpenAI API Integration für KI-gestützte Features
Acht Services, drei Datenbanken, KI-Integration, komplexe Abhängigkeiten. Genau der Typ Setup, der normalerweise Tage kostet.
So sieht das Ganze in der Praxis aus:
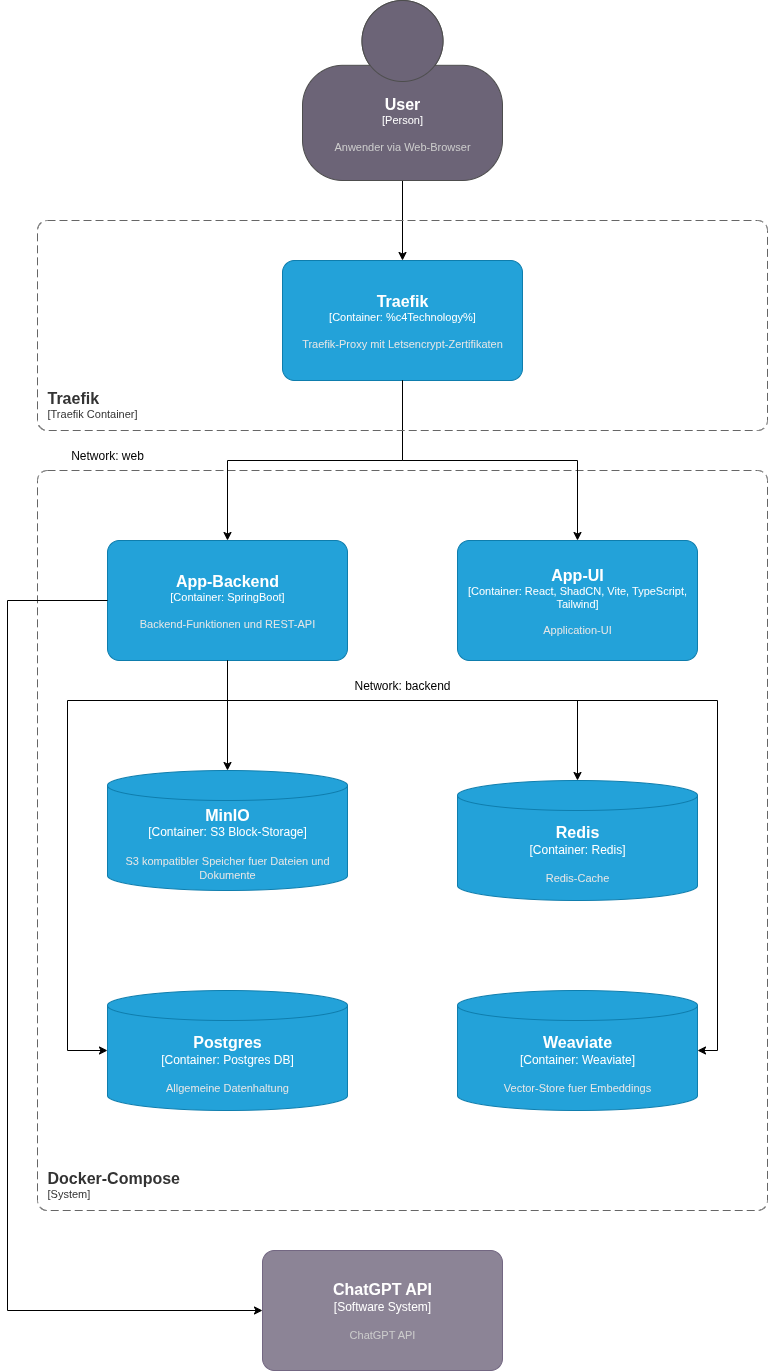
Abbildung: Alle Services laufen in Docker Compose mit strikter Netzwerk-Trennung zwischen Web- und Backend-Layer.
Das gesamte Setup startet mit einem einzigen Befehl: docker compose up -d_
Das Geheimnis: Profile und Umgebungstrennung
Der Schlüssel liegt in der intelligenten Nutzung von Docker Compose Profiles. Wir unterscheiden zwei Modi:
Dev-Profil: Nur Backend-Services laufen im Container
- Frontend läuft lokal (Hot-Reload, schnelles Development)
- Datenbanken und externe Services containerisiert
- Ports exponiert für direkten Zugriff mit GUI-Tools
Prod-Profil: Vollständiger Stack
- Alle Services containerisiert
- Traefik-Routing mit SSL
- Netzwerk-Isolation zwischen Web und Backend
- Security-Hardening aktiv
Ein simples export COMPOSE_PROFILES=dev entscheidet, welche Services starten. Keine separate Compose-Datei, keine Duplikation, keine Inkonsistenzen.
Die unterschätzten Game-Changer
Über die offensichtlichen Vorteile hinaus gibt es drei Aspekte, die in der Praxis den größten Unterschied machen:
1. Der "Saubere Slate" auf Knopfdruck
Jeder kennt das Problem: Die Entwicklungsumgebung läuft seit Wochen. Tests wurden ausgeführt, Daten manuell geändert, Debugging-Sessions haben Spuren hinterlassen. Plötzlich verhält sich das System anders als erwartet - aber liegt es am Code oder an den "dreckigen" Daten?
Mit Docker Compose:
docker compose down -v
docker compose up -d30 Sekunden später: Eine komplett frische Umgebung. Keine Altlasten, keine Artefakte, kein "aber bei mir funktioniert es". Das ist der Unterschied zwischen "probieren wir mal" und "wir wissen, dass es funktioniert".
2. Automatischer Datenbankaufbau mit Flyway
Die Datenbank startet nicht leer. Flyway-Migrationen laufen automatisch beim Start:
- Schema-Änderungen werden eingespielt
- Seed-Daten für Tests werden geladen
- Versionierung der DB-Struktur ist Teil des Codes
Ein neuer Entwickler bekommt nicht nur eine laufende DB, sondern eine DB im exakt richtigen Zustand - inklusive aller Migrationen, die in den letzten Monaten gelaufen sind.
3. Produktionsfehler nachstellen - in 5 Minuten
"Der Fehler tritt nur bei Kunden auf, die noch Version 2.3 nutzen." - Der Albtraum jedes Entwicklers.
Mit Docker Compose:
export CV_APP_TAG=2.3.0
export POSTGRES_TAG=16
docker compose up -dDie exakte Produktionsumgebung läuft lokal. Gleiche Versionen, gleiche Konfiguration, gleiche Datenbank-Migrationen. Der Fehler wird reproduzierbar, debuggbar, behebbar.
Keine VM, kein komplexes Setup, keine Woche Vorbereitung. Der Support-Call kommt rein, 5 Minuten später debuggt der Entwickler im exakten Setup des Kunden.
Traefik: Mehr als nur ein Reverse Proxy
Ein Detail, das oft übersehen wird: Traefik läuft in einem separaten Container und ist nicht Teil der Service-Stack-Definition. Das hat einen entscheidenden Vorteil.
In kleinen bis mittleren Produktionsumgebungen kann dieser eine Traefik-Container als Load Balancer für mehrere Anwendungen dienen:
# Ein Traefik für alle Projekte
traefik-container → cv-app-stack
→ crm-app-stack
→ analytics-app-stackStatt drei separate Load Balancer (oder drei nginx-Instanzen) zu konfigurieren und zu warten, managed ein einziger Traefik alle Routing-Regeln. SSL-Zertifikate? Let's Encrypt kümmert sich automatisch darum - für alle Domains.
Das Setup skaliert elegant: Von einem Projekt auf einem Server bis zu mehreren Stacks - ohne dass man die Architektur ändern muss.
Security: Pragmatisch statt dogmatisch
"Aber sind offene Datenbank-Ports nicht ein Security-Risk?" - Absolut berechtigt gefragt.
Die Antwort liegt im Kontext: Dev und Test sind nicht Produktion.
In Entwicklungs- und Testumgebungen:
- Ports sind bewusst exponiert für Debugging
- Entwickler nutzen GUI-Tools (DBeaver, RedisInsight, MinIO Console)
- Die Umgebungen laufen in isolierten, nicht-öffentlichen Netzwerken
- Trade-off: Entwicklerproduktivität vs. theoretisches Risiko
In Produktion:
- Zugriff nur über VPN oder Bastion Host
- Strikte Firewall-Regeln
- Monitoring und Alerting
- Das gleiche Compose-File, andere Umgebungsvariablen
Hier wird oft der Fehler gemacht, Dev-Umgebungen wie Fort Knox zu sichern, während Entwickler dann mit SSH-Tunneln und Port-Forwarding kämpfen. Das Ergebnis: Verschwendete Zeit und frustrierte Teams.
Die Kunst liegt darin, den richtigen Trade-off zu finden.
Security-Hardening: Wo es zählt
Wo wir keine Kompromisse machen: Container-Security.
Jeder Service läuft mit:
Read-only Filesystem: Verhindert Manipulation zur Laufzeit
Non-root User (UID 1001): Minimale Privilegien
Dropped Capabilities:
cap_drop: ALL- nur was wirklich benötigt wirdNo new privileges: Verhindert Privilege-Escalation
tmpfs für temporäre Daten: Beschränkter, flüchtiger Speicher
cv-app: user: "1001:1001" read_only: true tmpfs: - /tmp:rw,noexec,nosuid,nodev,size=100m security_opt: - no-new-privileges:true cap_drop: - ALL
Das ist kein Overhead - es ist Standard-Konfiguration, die einmal aufgesetzt wird und dann für alle Umgebungen gilt.
Netzwerk-Isolation: Defense in Depth
Zwei getrennte Docker-Networks schaffen klare Grenzen:
Web-Network: Internet-facing
- Traefik Proxy
- UI-Service
- API-Gateway
Backend-Network: Internal only
- Datenbanken (Postgres, Redis, Weaviate)
- Object Storage (MinIO)
- Interne Services
Ein kompromittierter Container im Web-Network hat keinen direkten Zugriff auf die Datenbanken. Defense in Depth - praktisch umgesetzt, nicht nur auf Slides.
Umgebungsvariablen: Das unterschätzte Problem
Ein oft übersehener Aspekt: Wie verwaltet man Konfiguration über verschiedene Umgebungen?
Die schlechte Lösung: Passwörter im Git-Repository Die komplizierte Lösung: Vault, Secrets-Manager, komplexe Toolchains Die pragmatische Lösung: Stage-spezifische .env-Dateien, außerhalb von Git
.env.dev # Für lokale Entwicklung
.env.test # Für Test-Environment
.env.staging # Für Abnahme
.env.prod # Für Produktion (verschlüsselt gespeichert)Ein simples source .env.dev vor dem docker compose up - fertig.
Für Produktion: Secrets über CI/CD-Pipeline injiziert oder verschlüsselt mit SOPS/Age gespeichert. Aber nicht jede Umgebung braucht Enterprise-Grade Secrets-Management.
Der Workflow in der Praxis
Neuer Entwickler im Team:
git clone projekt-repo
cp .env.example .env.dev
# API-Keys eintragen
docker compose --profile dev up -d4 Befehle, 5 Minuten - der Entwickler ist produktiv.
Deployment in Test:
ssh test-server
git pull
docker compose --profile prod pull
docker compose --profile prod up -d --force-recreateZero-Downtime-Deployment? Health-Checks in der Compose-Datei regeln das:
healthcheck:
test: ["CMD-SHELL", "curl -f http://localhost:8080/actuator/health || exit 1"]
interval: 30s
timeout: 10s
retries: 3
start_period: 60sDocker wartet, bis Services healthy sind, bevor alte Container gestoppt werden.
Lessons Learned: Was ich anders machen würde
Nach mehreren Projekten mit diesem Setup - einige Erkenntnisse:
1. Investiere Zeit in die initiale Compose-Datei Die ersten 2-3 Tage Setup zahlen sich über die Projektlaufzeit hundertfach aus. Jede Stunde hier spart später Tage.
2. Health-Checks sind nicht optional Ohne Health-Checks startest du möglicherweise Services, bevor die DB bereit ist. Das führt zu mysteriösen Fehlern und Debugging-Sessions.
3. Version-Pinning ist dein Freundpostgres:latest ist bequem - bis ein Update alles bricht. postgres:17 schafft Reproduzierbarkeit.
4. Dokumentiere deine Trade-offs Warum sind Ports offen? Warum dieser Ansatz statt jenem? Zukünftiges Du (und dein Team) werden es dir danken.
5. Ein Compose-File, multiple Stages Der Versuch, separate Compose-Dateien für jede Umgebung zu pflegen, endet in Chaos. Ein File, gesteuert über Env-Variablen und Profile.
Der ROI: Zahlen, die überzeugen
Zurück zu unserem Montag-Morgen-Szenario. Mit Docker Compose:
Vorher:
- Setup-Zeit: 16-24 Stunden pro Entwickler
- Inkonsistenzen zwischen Umgebungen: häufig
- Debugging von Umgebungsproblemen: wöchentlich mehrere Stunden
- Kosten pro Jahr: €160.000+
Nachher:
- Setup-Zeit: 5 Minuten
- Inkonsistenzen: faktisch eliminiert
- Debugging von Umgebungsproblemen: selten
- Kosten für initialen Setup: ca. 16 Stunden = €1.280
- Einsparung im ersten Jahr: €158.720
Und das berücksichtigt noch nicht die weichen Faktoren: Weniger Frustration, schnellere Onboarding-Zeit, mehr Zeit für Features statt Infrastructure.
Für wen ist das geeignet?
Docker Compose ist kein Silver Bullet. Es passt nicht für:
- Hochskalierte Microservice-Architekturen (100+ Services)
- Multi-Region-Deployments mit komplexem Routing
- Umgebungen, die automatisches Scaling benötigen
Es ist perfekt für:
- Startups und Scale-ups bis 50 Entwickler
- SaaS-Produkte mit 5-20 Services
- Agenturen mit mehreren Kundenprojekten
- Jedes Team, das Zeit mit Umgebungs-Setup verschwendet
Der Skalierungspfad: Von Compose zu Kubernetes
Ein oft unterschätzter Vorteil: Docker Compose ist kein Sackgassen-Investment. Wenn Ihr Projekt wächst und echtes Kubernetes braucht, ist die Migration überraschend einfach.
Warum? Weil die Container-Struktur bereits steht:
- Images sind gebaut und getestet
- Umgebungsvariablen sind dokumentiert
- Netzwerk-Topologie ist definiert
- Health-Checks sind implementiert
Tools wie Kompose konvertieren Compose-Dateien automatisch zu Kubernetes-Manifesten. Die Migration ist kein Rewrite, sondern ein Lift-and-Shift.
Die Empfehlung: Startet mit Compose. Wenn ihr wirklich Kubernetes braucht (nicht weil es auf Konferenzen cool klingt, sondern weil ihr echte Probleme habt), habt ihr eine solide Basis für die Migration. Bis dahin: Keep it simple.
Der erste Schritt
Die Frage ist nicht, ob Docker Compose das richtige Tool ist. Die Frage ist: Wie viel Zeit verliert Ihr Team aktuell mit Umgebungs-Setup?
Rechnen Sie es durch:
- Anzahl Entwickler × Stunden für Setup × Stundensatz × Anzahl Setups pro Jahr
Wenn die Zahl vierstellig ist, lohnt sich der Invest. Wenn sie fünfstellig ist, sollten Sie gestern angefangen haben.
Über den Autor: Andre Jahn unterstützt Unternehmen dabei, ihre Entwicklungsprozesse zu optimieren und Infrastructure as Code pragmatisch umzusetzen. Mit über 20 Jahren Erfahrung in der Software-Entwicklung und DevOps liegt der Fokus auf Lösungen, die tatsächlich funktionieren - nicht nur auf Slides.